(cherry picked from commit 20b5669269)
(cherry picked from commit 1574643a6a)
Update semantic version according to specification
(cherry picked from commit 22510f4130)
Mise à jour de 'Makefile'
(cherry picked from commit c3d85d8409)
(cherry picked from commit 5ea2309851)
(cherry picked from commit 4f3970e6c4)
[API] [SEMVER] replace number with version
[API] [SEMVER] [v1.20] less is replaced by css
(cherry picked from commit 43a3a40825)
(cherry picked from commit 669cea25bb)
(cherry picked from commit e25190d2b4)
(cherry picked from commit 5df876e19e)
(cherry picked from commit fc94f6fae2)
(cherry picked from commit 58c50c1fe4)
Backport #24487 by @fnetX
On the @Forgejo instance of Codeberg, we discovered that forking a repo
which is already forked now returns a 500 Internal Server Error, which
is unexpected. This is an attempt at fixing this.
The error message in the log:
~~~
2023/05/02 08:36:30 .../api/v1/repo/fork.go:147:CreateFork() [E]
[6450cb8e-113] ForkRepository: repository is already forked by user
[uname: ...., repo path: .../..., fork path: .../...]
~~~
The service that is used for forking returns a custom error message
which is not checked against.
About the order of options:
The case that the fork already exists should be more common, followed by
the case that a repo with the same name already exists for other
reasons. The case that the global repo limit is hit is probably not the
likeliest.
---------
Co-authored-by: Otto Richter (fnetX) <git@fralix.ovh>
Backport #24362 by @jolheiser
> The scoped token PR just checked all API routes but in fact, some web
routes like `LFS`, git `HTTP`, container, and attachments supports basic
auth. This PR added scoped token check for them.
Signed-off-by: jolheiser <john.olheiser@gmail.com>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Backport #24194 by @harryzcy
- [x] Identify endpoints that should be public
- [x] Update integration tests
Fix#24159
Co-authored-by: harryzcy <harry@harryzheng.com>
Backport #24202Close#24195
Fix the bug:
1. The old code doesn't handle `removedfile` event correctly
2. The old code doesn't provide attachments for type=CommentTypeReview
---------
Co-authored-by: silverwind <me@silverwind.io>
Backport #23786
Refactor commit status for Actions jobs (#23786)
Highlights:
- Treat `StatusSkipped` as `CommitStatusSuccess` instead of
`CommitStatusFailure`, so it fixed#23599.
- Use the bot user `gitea-actions` instead of the trigger as the creator
of commit status.
- New format `<run_name> / <job_name> / (<event>)` for the context of
commit status to avoid conflicts.
- Add descriptions for commit status.
- Add the missing calls to `CreateCommitStatus`.
- Refactor `CreateCommitStatus` to make it easier to use.
Co-authored-by: Jason Song <i@wolfogre.com>
Backport #23944 by @sillyguodong
Fix#23943
When trigger event is `release`, ref should be like
`refs/tags/<tag_name>` instead of `CommitID`
Co-authored-by: sillyguodong <33891828+sillyguodong@users.noreply.github.com>
Backport #23823 by @wxiaoguang
Thanks to @trwnh
Close#23802
The ActivityPub id is an HTTPS URI that should remain constant, even if
the user changes their name.
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Backport #23552 by @atomaka
When attempting to migrate a repository via the API endpoint comments
are always included. This can create a problem if your source repository
has issues or pull requests but you do not want to import them into
Gitea that displays as something like:
> Error 500: We were unable to perform the request due to server-side
problems. 'comment references non existent IssueIndex 4
There are only two ways to resolve this:
1. Migrate using the web interface
2. Migrate using the API including at issues or pull requests.
This PR matches the behavior of the API migration router to the web
migration router.
Co-authored-by: Andrew Tomaka <atomaka@atomaka.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Backport #23387Close#22934
In `/user/repos` API (and other APIs related to creating repos), user
can specify a readme template for auto init. At present, if the
specified template does not exist, a `500` will be returned . This PR
improved the logic and will return a `400` instead of `500`.
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Backport #23451 by @jolheiser
This PR just adds the `purge` query parameter to the swagger docs for
admin user delete.
I considered using the same verbiage we have in the UI, but that seemed
more verbose than descriptions we use elsewhere in swagger. I'm fine if
that's preferred, though, just let me know. 🙂
Signed-off-by: jolheiser <john.olheiser@gmail.com>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Backport #23406 by @baez90
When creating attachments (issue, release, repo) the file size (being
part of the multipart file header) is passed through the chain of
creating an attachment to ensure the MinIO client can stream the file
directly instead of having to read it to memory completely at first.
Fixes#23393
Co-authored-by: Peter <peter.kurfer@googlemail.com>
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Backport #23372Fix#23357 .
Now the `/repos/{owner}/{repo}/git/notes/{sha}` API supports getting
notes by a ref or sha
(https://try.gitea.io/api/swagger#/repository/repoGetNote). But the
`GetNote` func can only accept commit ID.
a12f575737/modules/git/notes_nogogit.go (L18)
So we need to convert the query parameter to commit ID before calling
`GetNote`.
Co-authored-by: Zettat123 <zettat123@gmail.com>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Backport #23216
When creating commit status for Actons jobs, a payload with nil
`HeadCommit` will cause panic.
Reported at:
https://gitea.com/gitea/act_runner/issues/28#issuecomment-732166
Although the `HeadCommit` probably can not be nil after #23215,
`CreateCommitStatus` should protect itself, to avoid being broken in the
future.
In addition, it's enough to print error log instead of returning err
when `CreateCommitStatus` failed.
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Backport #22976
Extract from #11669 and enhancement to #22585 to support exclusive
scoped labels in label templates
* Move label template functionality to label module
* Fix handling of color codes
* Add Advanced label template
Co-authored-by: Lauris BH <lauris@nix.lv>
Backport #23162
The name of the job or step comes from the workflow file, while the name
of the runner comes from its registration. If the strings used for these
names are too long, they could cause db issues.
Co-authored-by: Jason Song <i@wolfogre.com>
The API to create tokens is missing the ability to set the required
scopes for tokens, and to show them on the API and on the UI.
This PR adds this functionality.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Close: #22910
---
I'm confused about that why does the api (`GET
/repos/{owner}/{repo}/pulls/{index}/files`) require caller to pass the
parameters `limit` and `page`.
In my case, the caller only needs to pass a `skip-to` to paging. This is
consistent with the api `GET /{owner}/{repo}/pulls/{index}/files`
So, I deleted the code related to `listOptions`
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Some bugs caused by less unit tests in fundamental packages. This PR
refactor `setting` package so that create a unit test will be easier
than before.
- All `LoadFromXXX` files has been splited as two functions, one is
`InitProviderFromXXX` and `LoadCommonSettings`. The first functions will
only include the code to create or new a ini file. The second function
will load common settings.
- It also renames all functions in setting from `newXXXService` to
`loadXXXSetting` or `loadXXXFrom` to make the function name less
confusing.
- Move `XORMLog` to `SQLLog` because it's a better name for that.
Maybe we should finally move these `loadXXXSetting` into the `XXXInit`
function? Any idea?
---------
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: delvh <dev.lh@web.de>
This PR refactors and improves the password hashing code within gitea
and makes it possible for server administrators to set the password
hashing parameters
In addition it takes the opportunity to adjust the settings for `pbkdf2`
in order to make the hashing a little stronger.
The majority of this work was inspired by PR #14751 and I would like to
thank @boppy for their work on this.
Thanks to @gusted for the suggestion to adjust the `pbkdf2` hashing
parameters.
Close#14751
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Allow back-dating user creation via the `adminCreateUser` API operation.
`CreateUserOption` now has an optional field `created_at`, which can
contain a datetime-formatted string. If this field is present, the
user's `created_unix` database field will be updated to its value.
This is important for Blender's migration of users from Phabricator to
Gitea. There are many users, and the creation timestamp of their account
can give us some indication as to how long someone's been part of the
community.
The back-dating is done in a separate query that just updates the user's
`created_unix` field. This was the easiest and cleanest way I could
find, as in the initial `INSERT` query the field always is set to "now".
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Add setting to allow edits by maintainers by default, to avoid having to
often ask contributors to enable this.
This also reorganizes the pull request settings UI to improve clarity.
It was unclear which checkbox options were there to control available
merge styles and which merge styles they correspond to.
Now there is a "Merge Styles" label followed by the merge style options
with the same name as in other menus. The remaining checkboxes were
moved to the bottom, ordered rougly by typical order of operations.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fixes#19555
Test-Instructions:
https://github.com/go-gitea/gitea/pull/21441#issuecomment-1419438000
This PR implements the mapping of user groups provided by OIDC providers
to orgs teams in Gitea. The main part is a refactoring of the existing
LDAP code to make it usable from different providers.
Refactorings:
- Moved the router auth code from module to service because of import
cycles
- Changed some model methods to take a `Context` parameter
- Moved the mapping code from LDAP to a common location
I've tested it with Keycloak but other providers should work too. The
JSON mapping format is the same as for LDAP.
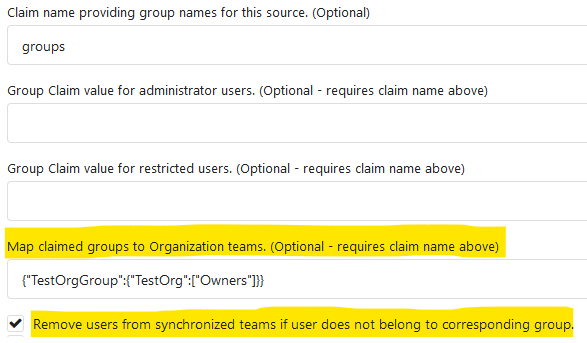
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
The `commit_id` property name is the same as equivalent functionality in
GitHub. If the action was not caused by a commit, an empty string is
used.
This can for example be used to automatically add a Resolved label to an
issue fixed by a commit, or clear it when the issue is reopened.
This PR adds the support for scopes of access tokens, mimicking the
design of GitHub OAuth scopes.
The changes of the core logic are in `models/auth` that `AccessToken`
struct will have a `Scope` field. The normalized (no duplication of
scope), comma-separated scope string will be stored in `access_token`
table in the database.
In `services/auth`, the scope will be stored in context, which will be
used by `reqToken` middleware in API calls. Only OAuth2 tokens will have
granular token scopes, while others like BasicAuth will default to scope
`all`.
A large amount of work happens in `routers/api/v1/api.go` and the
corresponding `tests/integration` tests, that is adding necessary scopes
to each of the API calls as they fit.
- [x] Add `Scope` field to `AccessToken`
- [x] Add access control to all API endpoints
- [x] Update frontend & backend for when creating tokens
- [x] Add a database migration for `scope` column (enable 'all' access
to past tokens)
I'm aiming to complete it before Gitea 1.19 release.
Fixes#4300
This PR introduce glob match for protected branch name. The separator is
`/` and you can use `*` matching non-separator chars and use `**` across
separator.
It also supports input an exist or non-exist branch name as matching
condition and branch name condition has high priority than glob rule.
Should fix#2529 and #15705
screenshots
<img width="1160" alt="image"
src="https://user-images.githubusercontent.com/81045/205651179-ebb5492a-4ade-4bb4-a13c-965e8c927063.png">
Co-authored-by: zeripath <art27@cantab.net>
The API endpoints for "git" can panic if they are called on an empty
repo. We can simply allow empty repos for these endpoints without worry
as they should just work.
Fix#22452
Signed-off-by: Andrew Thornton <art27@cantab.net>
- Move the file `compare.go` and `slice.go` to `slice.go`.
- Fix `ExistsInSlice`, it's buggy
- It uses `sort.Search`, so it assumes that the input slice is sorted.
- It passes `func(i int) bool { return slice[i] == target })` to
`sort.Search`, that's incorrect, check the doc of `sort.Search`.
- Conbine `IsInt64InSlice(int64, []int64)` and `ExistsInSlice(string,
[]string)` to `SliceContains[T]([]T, T)`.
- Conbine `IsSliceInt64Eq([]int64, []int64)` and `IsEqualSlice([]string,
[]string)` to `SliceSortedEqual[T]([]T, T)`.
- Add `SliceEqual[T]([]T, T)` as a distinction from
`SliceSortedEqual[T]([]T, T)`.
- Redesign `RemoveIDFromList([]int64, int64) ([]int64, bool)` to
`SliceRemoveAll[T]([]T, T) []T`.
- Add `SliceContainsFunc[T]([]T, func(T) bool)` and
`SliceRemoveAllFunc[T]([]T, func(T) bool)` for general use.
- Add comments to explain why not `golang.org/x/exp/slices`.
- Add unit tests.
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}