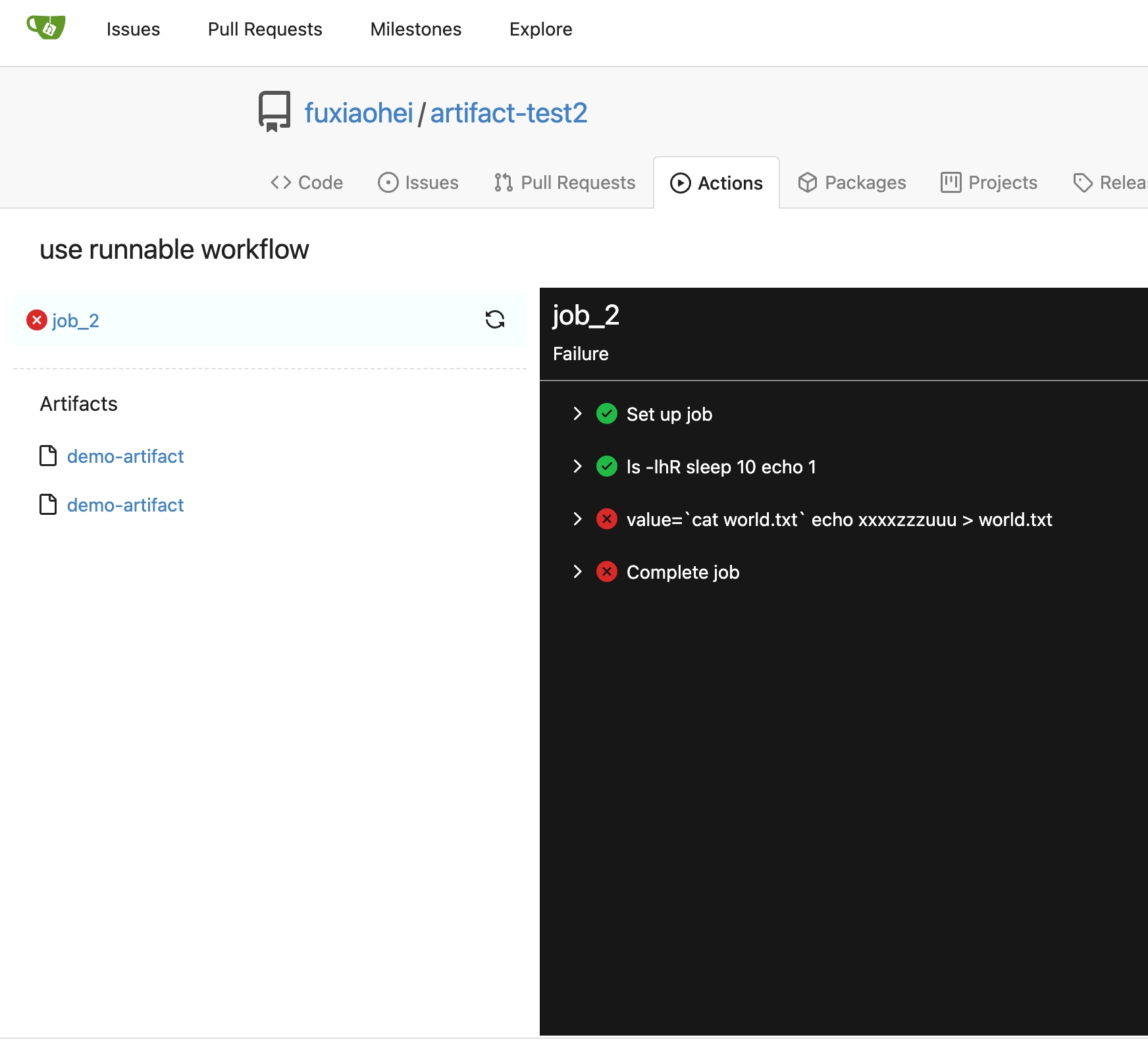
Fix#25934
Add `ignoreGlobal` parameter to `reqUnitAccess` and only check global
disabled units when `ignoreGlobal` is true. So the org-level projects
and user-level projects won't be affected by global disabled
`repo.projects` unit.
Fixes (?) #25538
Fixes https://codeberg.org/forgejo/forgejo/issues/972
Regression #23879#23879 introduced a change which prevents read access to packages if a
user is not a member of an organization.
That PR also contained a change which disallows package access if the
team unit is configured with "no access" for packages. I don't think
this change makes sense (at the moment). It may be relevant for private
orgs. But for public or limited orgs that's useless because an
unauthorized user would have more access rights than the team member.
This PR restores the old behaviour "If a user has read access for an
owner, they can read packages".
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Fix#25558
Extract from #22743
This PR added a repository's check when creating/deleting branches via
API. Mirror repository and archive repository cannot do that.
Related #14180
Related #25233
Related #22639Close#19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Enable deduplication of unofficial reviews. When pull requests are
configured to include all approvers, not just official ones, in the
default merge messages it was possible to generate duplicated
Reviewed-by lines for a single person. Add an option to find only
distinct reviews for a given query.
fixes#24795
---------
Signed-off-by: Cory Todd <cory.todd@canonical.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Fixes#24145
To solve the bug, I added a "computed" `TargetBehind` field to the
`Release` model, which indicates the target branch of a release.
This is particularly useful if the target branch was deleted in the
meantime (or is empty).
I also did a micro-optimization in `calReleaseNumCommitsBehind`. Instead
of checking that a branch exists and then call `GetBranchCommit`, I
immediately call `GetBranchCommit` and handle the `git.ErrNotExist`
error.
This optimization is covered by the added unit test.
At first, we have one unified team unit permission which is called
`Team.Authorize` in DB.
But since https://github.com/go-gitea/gitea/pull/17811, we allowed
different units to have different permission.
The old code is only designed for the old version. So after #17811, if
org users have write permission of other units, but have no permission
of packages, they can also get write permission of packages.
Co-authored-by: delvh <dev.lh@web.de>
`namedBlob` turned out to be a poor imitation of a `TreeEntry`. Using
the latter directly shortens this code.
This partially undoes https://github.com/go-gitea/gitea/pull/23152/,
which I found a merge conflict with, and also expands the test it added
to cover the subtle README-in-a-subfolder case.
Add test coverage to the important features of
[`routers.web.repo.renderReadmeFile`](067b0c2664/routers/web/repo/view.go (L273));
namely that:
- it can handle looking in docs/, .gitea/, and .github/
- it can handle choosing between multiple competing READMEs
- it prefers the localized README to the markdown README to the
plaintext README
- it can handle broken symlinks when processing all the options
- it uses the name of the symlink, not the name of the target of the
symlink
`renderReadmeFile` needs `readmeTreelink` as parameter but gets
`treeLink`.
The values of them look like as following:
`treeLink`: `/{OwnerName}/{RepoName}/src/branch/{BranchName}`
`readmeTreelink`:
`/{OwnerName}/{RepoName}/src/branch/{BranchName}/{ReadmeFileName}`
`path.Dir` in
8540fc45b1/routers/web/repo/view.go (L316)
should convert `readmeTreelink` into
`/{OwnerName}/{RepoName}/src/branch/{BranchName}` instead of the current
`/{OwnerName}/{RepoName}/src/branch`.
Fixes#23151
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
During the recent hash algorithm change it became clear that the choice
of password hash algorithm plays a role in the time taken for CI to run.
Therefore as attempt to improve CI we should consider using a dummy
hashing algorithm instead of a real hashing algorithm.
This PR creates a dummy algorithm which is then set as the default
hashing algorithm during tests that use the fixtures. This hopefully
will cause a reduction in the time it takes for CI to run.
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR refactors and improves the password hashing code within gitea
and makes it possible for server administrators to set the password
hashing parameters
In addition it takes the opportunity to adjust the settings for `pbkdf2`
in order to make the hashing a little stronger.
The majority of this work was inspired by PR #14751 and I would like to
thank @boppy for their work on this.
Thanks to @gusted for the suggestion to adjust the `pbkdf2` hashing
parameters.
Close#14751
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Fix#21994.
And fix#19470.
While generating new repo from a template, it does something like
"commit to git repo, re-fetch repo model from DB, and update default
branch if it's empty".
19d5b2f922/modules/repository/generate.go (L241-L253)
Unfortunately, when load repo from DB, the default branch will be set to
`setting.Repository.DefaultBranch` if it's empty:
19d5b2f922/models/repo/repo.go (L228-L233)
I believe it's a very old temporary patch but has been kept for many
years, see:
[2d2d85bb](https://github.com/go-gitea/gitea/commit/2d2d85bb#diff-1851799b06733db4df3ec74385c1e8850ee5aedee70b8b55366910d22725eea8)
I know it's a risk to delete it, may lead to potential behavioral
changes, but we cannot keep the outdated `FIXME` forever. On the other
hand, an empty `DefaultBranch` does make sense: an empty repo doesn't
have one conceptually (actually, Gitea will still set it to
`setting.Repository.DefaultBranch` to make it safer).
- Currently the function `GetUsersWhoCanCreateOrgRepo` uses a query that
is able to have duplicated users in the result, this is can happen under
the condition that a user is in team that either is the owner team or
has permission to create organization repositories.
- Add test code to simulate the above condition for user 3,
[`TestGetUsersWhoCanCreateOrgRepo`](a1fcb1cfb8/models/organization/org_test.go (L435))
is the test function that tests for this.
- The fix is quite trivial use a map keyed by user id in order to drop
duplicates.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix#22386
`GetDirectorySize` moved as `getDirectorySize` because it becomes a
special function which should not be put in `util`.
Co-authored-by: Jason Song <i@wolfogre.com>
Some dbs require that all tables have primary keys, see
- #16802
- #21086
We can add a test to keep it from being broken again.
Edit:
~Added missing primary key for `ForeignReference`~ Dropped the
`ForeignReference` table to satisfy the check, so it closes#21086.
More context can be found in comments.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: zeripath <art27@cantab.net>
The OAuth spec [defines two types of
client](https://datatracker.ietf.org/doc/html/rfc6749#section-2.1),
confidential and public. Previously Gitea assumed all clients to be
confidential.
> OAuth defines two client types, based on their ability to authenticate
securely with the authorization server (i.e., ability to
> maintain the confidentiality of their client credentials):
>
> confidential
> Clients capable of maintaining the confidentiality of their
credentials (e.g., client implemented on a secure server with
> restricted access to the client credentials), or capable of secure
client authentication using other means.
>
> **public
> Clients incapable of maintaining the confidentiality of their
credentials (e.g., clients executing on the device used by the resource
owner, such as an installed native application or a web browser-based
application), and incapable of secure client authentication via any
other means.**
>
> The client type designation is based on the authorization server's
definition of secure authentication and its acceptable exposure levels
of client credentials. The authorization server SHOULD NOT make
assumptions about the client type.
https://datatracker.ietf.org/doc/html/rfc8252#section-8.4
> Authorization servers MUST record the client type in the client
registration details in order to identify and process requests
accordingly.
Require PKCE for public clients:
https://datatracker.ietf.org/doc/html/rfc8252#section-8.1
> Authorization servers SHOULD reject authorization requests from native
apps that don't use PKCE by returning an error message
Fixes#21299
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
At the moment a repository reference is needed for webhooks. With the
upcoming package PR we need to send webhooks without a repository
reference. For example a package is uploaded to an organization. In
theory this enables the usage of webhooks for future user actions.
This PR removes the repository id from `HookTask` and changes how the
hooks are processed (see `services/webhook/deliver.go`). In a follow up
PR I want to remove the usage of the `UniqueQueue´ and replace it with a
normal queue because there is no reason to be unique.
Co-authored-by: 6543 <6543@obermui.de>
depends on #18871
Added some api integration tests to help testing of #18798.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
This adds an api endpoint `/files` to PRs that allows to get a list of changed files.
built upon #18228, reviews there are included
closes https://github.com/go-gitea/gitea/issues/654
Co-authored-by: Anton Bracke <anton@ju60.de>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Fixes#21206
If user and viewer are equal the method should return true.
Also the common organization check was wrong as `count` can never be
less then 0.
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
- Currently the function takes in the `UserID` option, but isn't being
used within the SQL query. This patch fixes that by checking that only
teams are being returned that the user belongs to.
Fix#20829
Co-authored-by: delvh <dev.lh@web.de>
Milestones in archived repos should not be displayed on `/milestones`. Therefore
we should exclude these repositories from milestones page.
Fix#18257
Signed-off-by: Andrew Thornton <art27@cantab.net>
- Don't use hacky solution to limit to the correct RepoID's, instead use
current code to handle these limits. The existing code is more correct
than the hacky solution.
- Resolves#19636
- Add test-case
* GetFeeds must always discard actions with dangling repo_id
See https://discourse.gitea.io/t/blank-page-after-login/5051/12
for a panic in 1.16.6.
* add comment to explain the dangling ID in the fixture
* loadRepoOwner must not attempt to use a nil action.Repo
* make fmt
Co-authored-by: Loïc Dachary <loic@dachary.org>
Targeting #14936, #15332
Adds a collaborator permissions API endpoint according to GitHub API: https://docs.github.com/en/rest/collaborators/collaborators#get-repository-permissions-for-a-user to retrieve a collaborators permissions for a specific repository.
### Checks the repository permissions of a collaborator.
`GET` `/repos/{owner}/{repo}/collaborators/{collaborator}/permission`
Possible `permission` values are `admin`, `write`, `read`, `owner`, `none`.
```json
{
"permission": "admin",
"role_name": "admin",
"user": {}
}
```
Where `permission` and `role_name` hold the same `permission` value and `user` is filled with the user API object. Only admins are allowed to use this API endpoint.
Storing the foreign identifier of an imported issue in the database is a prerequisite to implement idempotent migrations or mirror for issues. It is a baby step towards mirroring that introduces a new table.
At the moment when an issue is created by the Gitea uploader, it fails if the issue already exists. The Gitea uploader could be modified so that, instead of failing, it looks up the database to find an existing issue. And if it does it would update the issue instead of creating a new one. However this is not currently possible because an information is missing from the database: the foreign identifier that uniquely represents the issue being migrated is not persisted. With this change, the foreign identifier is stored in the database and the Gitea uploader will then be able to run a query to figure out if a given issue being imported already exists.
The implementation of mirroring for issues, pull requests, releases, etc. can be done in three steps:
1. Store an identifier for the element being mirrored (issue, pull request...) in the database (this is the purpose of these changes)
2. Modify the Gitea uploader to be able to update an existing repository with all it contains (issues, pull request...) instead of failing if it exists
3. Optimize the Gitea uploader to speed up the updates, when possible.
The second step creates code that does not yet exist to enable idempotent migrations with the Gitea uploader. When a migration is done for the first time, the behavior is not changed. But when a migration is done for a repository that already exists, this new code is used to update it.
The third step can use the code created in the second step to optimize and speed up migrations. For instance, when a migration is resumed, an issue that has an update time that is not more recent can be skipped and only newly created issues or updated ones will be updated. Another example of optimization could be that a webhook notifies Gitea when an issue is updated. The code triggered by the webhook would download only this issue and call the code created in the second step to update the issue, as if it was in the process of an idempotent migration.
The ForeignReferences table is added to contain local and foreign ID pairs relative to a given repository. It can later be used for pull requests and other artifacts that can be mirrored. Although the foreign id could be added as a single field in issues or pull requests, it would need to be added to all tables that represent something that can be mirrored. Creating a new table makes for a simpler and more generic design. The drawback is that it requires an extra lookup to obtain the information. However, this extra information is only required during migration or mirroring and does not impact the way Gitea currently works.
The foreign identifier of an issue or pull request is similar to the identifier of an external user, which is stored in reactions, issues, etc. as OriginalPosterID and so on. The representation of a user is however different and the ability of users to link their account to an external user at a later time is also a logic that is different from what is involved in mirroring or migrations. For these reasons, despite some commonalities, it is unclear at this time how the two tables (foreign reference and external user) could be merged together.
The ForeignID field is extracted from the issue migration context so that it can be dumped in files with dump-repo and later restored via restore-repo.
The GetAllComments downloader method is introduced to simplify the implementation and not overload the Context for the purpose of pagination. It also clarifies in which context the comments are paginated and in which context they are not.
The Context interface is no longer useful for the purpose of retrieving the LocalID and ForeignID since they are now both available from the PullRequest and Issue struct. The Reviewable and Commentable interfaces replace and serve the same purpose.
The Context data member of PullRequest and Issue becomes a DownloaderContext to clarify that its purpose is not to support in memory operations while the current downloader is acting but is not otherwise persisted. It is, for instance, used by the GitLab downloader to store the IsMergeRequest boolean and sort out issues.
---
[source](https://lab.forgefriends.org/forgefriends/forgefriends/-/merge_requests/36)
Signed-off-by: Loïc Dachary <loic@dachary.org>
Co-authored-by: Loïc Dachary <loic@dachary.org>
* add test coverage for original author conversion during migrations
And create a function to factorize a code snippet that is repeated
five times and would otherwise be more difficult to test and maintain
consistently.
Signed-off-by: Loïc Dachary <loic@dachary.org>
* fix variable scope and int64 formatting
* add missing calls to remapExternalUser and fix misplaced %d
Co-authored-by: Loïc Dachary <loic@dachary.org>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Migrate from U2F to Webauthn
Co-authored-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* migrations: a deadline at January 1st, 1970 is valid
Do not change the deadline value if it is set to January 1st, 1970.
Setting the deadline to year 9999 when it is zero (which is equal to
January 1st, 1970) modifies a deadline set to January 1st, 1970 which
is a valid date. In addition, setting a date in year 9999 will be
converted to a null date in some cases.
Signed-off-by: Loïc Dachary <loic@dachary.org>
* tests: set milestone.deadline_unix in fixtures
The value of deadline_unix must be set to 253370764800 (i.e. 9999-01-01) in
fixtures, otherwise it will be inserted as null which leads to
unexpected errors. For instance, DumpRepository will store a null
deadline_unix as 0 (i.e. 1970-01-01) and RestoreRepository will change
it to 9999-01-01.
Signed-off-by: Loïc Dachary <loic@dachary.org>
Co-authored-by: Loïc Dachary <loic@dachary.org>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* Team permission allow different unit has different permission
* Finish the interface and the logic
* Fix lint
* Fix translation
* align center for table cell content
* Fix fixture
* merge
* Fix test
* Add deprecated
* Improve code
* Add tooltip
* Fix swagger
* Fix newline
* Fix tests
* Fix tests
* Fix test
* Fix test
* Max permission of external wiki and issues should be read
* Move team units with limited max level below units table
* Update label and column names
* Some improvements
* Fix lint
* Some improvements
* Fix template variables
* Add permission docs
* improve doc
* Fix fixture
* Fix bug
* Fix some bug
* fix
* gofumpt
* Integration test for migration (#18124)
integrations: basic test for Gitea {dump,restore}-repo
This is a first step for integration testing of DumpRepository and
RestoreRepository. It:
runs a Gitea server,
dumps a repo via DumpRepository to the filesystem,
restores the repo via RestoreRepository from the filesystem,
dumps the restored repository to the filesystem,
compares the first and second dump and expects them to be identical
The verification is trivial and the goal is to add more tests for each
topic of the dump.
Signed-off-by: Loïc Dachary <loic@dachary.org>
* Team permission allow different unit has different permission
* Finish the interface and the logic
* Fix lint
* Fix translation
* align center for table cell content
* Fix fixture
* merge
* Fix test
* Add deprecated
* Improve code
* Add tooltip
* Fix swagger
* Fix newline
* Fix tests
* Fix tests
* Fix test
* Fix test
* Max permission of external wiki and issues should be read
* Move team units with limited max level below units table
* Update label and column names
* Some improvements
* Fix lint
* Some improvements
* Fix template variables
* Add permission docs
* improve doc
* Fix fixture
* Fix bug
* Fix some bug
* Fix bug
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Aravinth Manivannan <realaravinth@batsense.net>
They were previously not covered at all, either by integration tests or unit tests.
This PR also fixes a bug where the `num_comments` field was incorrectly set to include all types of comments.
It sets num_closed_issues: 0 as default in milestone unit test fixtures. If they are not set, Incr("num_closed_issues") will be a noop because the field is null.
This change enables the usage of U2F without being forced to enroll an TOTP authenticator.
The `/user/auth/u2f` has been changed to hide the "use TOTP instead" bar if TOTP is not enrolled.
Fixes#5410Fixes#17495
There is a small bug in the way that repo access is checked in
repoAssignment: Accessibility is checked by checking if the user has a
marked access to the repository instead of checking if the user has any
team granted access.
This PR changes this permissions check to use HasAccess() which does the
correct test. There is also a fix in the release api ListReleases where
it should return draft releases if the user is a member of a team with
write access to the releases.
The PR also adds a testcase.
Signed-off-by: Andrew Thornton <art27@cantab.net>
It makes Admin's life easier to filter users by various status.
* introduce window.config.PageData to pass template data to javascript module and small refactor
move legacy window.ActivityTopAuthors to window.config.PageData.ActivityTopAuthors
make HTML structure more IDE-friendly in footer.tmpl and head.tmpl
remove incorrect <style class="list-search-style"></style> in head.tmpl
use log.Error instead of log.Critical in admin user search
* use LEFT JOIN instead of SubQuery when admin filters users by 2fa. revert non-en locale.
* use OptionalBool instead of status map
* refactor SearchUserOptions.toConds to SearchUserOptions.toSearchQueryBase
* add unit test for user search
* only allow admin to use filters to search users
- Update default branch if needed
- Update protected branch if needed
- Update all not merged pull request base branch name
- Rename git branch
- Record this rename work and auto redirect for old branch on ui
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: delvh <dev.lh@web.de>
* Fix commit status index problem
* remove unused functions
* Add fixture and test for migration
* Fix lint
* Fix fixture
* Fix lint
* Fix test
* Fix bug
* Fix bug
When create a new issue or comment and paste/upload an attachment/image, it will not assign an issue id before submit. So if user give up the creating, the attachments will lost key feature and become dirty content. We don't know if we need to delete the attachment even if the repository deleted.
This PR add a repo_id in attachment table so that even if a new upload attachment with no issue_id or release_id but should have repo_id. When deleting a repository, they could also be deleted.
Co-authored-by: 6543 <6543@obermui.de>
You can limit or hide organisations. This pull make it also posible for users
- new strings to translte
- add checkbox to user profile form
- add checkbox to admin user.edit form
- filter explore page user search
- filter api admin and public user searches
- allow admins view "hidden" users
- add app option DEFAULT_USER_VISIBILITY
- rewrite many files to use Visibility field
- check for teams intersection
- fix context output
- right fake 404 if not visible
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Andrew Thornton <art27@cantab.net>
* invent ctx.QueryOptionalBool
* [API] ListReleases add draft and pre-release filter
* Add X-Total-Count header
* Add a release to fixtures
* Add TEST for API ListReleases
* Add a new table issue_index to store the max issue index so that issue could be deleted with no duplicated index
* Fix pull index
* Add tests for concurrent creating issues
* Fix lint
* Fix tests
* Fix postgres test
* Add test for migration v180
* Rename wrong test file name
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lauris BH <lauris@nix.lv>
* Always store primary email address into email_address table and also the state
* Add lower_email to not convert email to lower as what's added
* Fix fixture
* Fix tests
* Use BeforeInsert to save lower email
* Fix v180 migration
* fix tests
* Fix test
* Remove wrong submited codes
* Fix test
* Fix test
* Fix test
* Add test for v181 migration
* remove change user's email to lower
* Revert change on user's email column
* Fix lower email
* Fix test
* Fix test
* fix some ui bug about draft release
- should not show draft release in tag list because
it will't create real tag
- still show draft release without tag and commit message
for draft release instead of 404 error
- remove tag load for attachement links because it's useless
Signed-off-by: a1012112796 <1012112796@qq.com>
* add test code
* fix test
That's because has added a new release in relaese test database.
* fix dropdown link for draft release
* API: fix set milestone on PR creation
pr creation via API failed with 404, because we searched
for milestoneID 0, due to uninitialized var usage D:
* add tests
* fix expected status codes
* fix tests
Co-authored-by: 6543 <6543@obermui.de>
* make repo as "pending transfer" if on transfer start doer has no right to create repo in new destination
* if new pending transfer ocured, create UI & Mail notifications
* Add redirect for user
* Add redirect for orgs
* Add user redirect test
* Appease linter
* Add comment to DeleteUserRedirect function
* Fix locale changes
* Fix GetUserByParams
* Fix orgAssignment
* Remove debug logging
* Add redirect prompt
* Dont Export DeleteUserRedirect & only use it within a session
* Unexport newUserRedirect
* cleanup
* Fix & Dedub API code
* Format Template
* Add Migration & rm dublicat
* Refactor: unexport newRepoRedirect() & rm dedub del exec
* if this fails we'll need to re-rename the user directory
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This is "minimal" in the sense that only the Authorization Code Flow
from OpenID Connect Core is implemented. No discovery, no configuration
endpoint, and no user scope management.
OpenID Connect is an extension to the (already implemented) OAuth 2.0
protocol, and essentially an `id_token` JWT is added to the access token
endpoint response when using the Authorization Code Flow. I also added
support for the "nonce" field since it is required to be used in the
id_token if the client decides to include it in its initial request.
In order to enable this extension an OAuth 2.0 scope containing
"openid" is needed. Other OAuth 2.0 requests should not be impacted by
this change.
This minimal implementation is enough to enable single sign-on (SSO)
for other sites, e.g. by using something like `mod_auth_openidc` to
only allow access to a CI server if a user has logged into Gitea.
Fixes: #1310
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: zeripath <art27@cantab.net>
* now uses the same permission model as for the activity feed:
only include activities in repos, that the doer has access to.
this might be somewhat slower.
* also improves handling of user.KeepActivityPrivate (still shows
the heatmap to self & admins)
* extend tests
* adjust integration test to new behaviour
* add access to actions for admins
* extend heatmap unit tests
* Make archival asynchronous
The prime benefit being sought here is for large archives to not
clog up the rendering process and cause unsightly proxy timeouts.
As a secondary benefit, archive-in-progress is moved out of the
way into a /tmp file so that new archival requests for the same
commit will not get fulfilled based on an archive that isn't yet
finished.
This asynchronous system is fairly primitive; request comes in, we'll
spawn off a new goroutine to handle it, then we'll mark it as done.
Status requests will see if the file exists in the final location,
and report the archival as done when it exists.
Fixes#11265
* Archive links: drop initial delay to three-quarters of a second
Some, or perhaps even most, archives will not take all that long to archive.
The archive process starts as soon as the download button is initially
clicked, so in theory they could be done quite quickly. Drop the initial
delay down to three-quarters of a second to make it more responsive in the
common case of the archive being quickly created.
* archiver: restructure a little bit to facilitate testing
This introduces two sync.Cond pointers to the archiver package. If they're
non-nil when we go to process a request, we'll wait until signalled (at all)
to proceed. The tests will then create the sync.Cond so that it can signal
at-will and sanity-check the state of the queue at different phases.
The author believes that nil-checking these two sync.Cond pointers on every
archive processing will introduce minimal overhead with no impact on
maintainability.
* gofmt nit: no space around binary + operator
* services: archiver: appease golangci-lint, lock queueMutex
Locking/unlocking the queueMutex is allowed, but not required, for
Cond.Signal() and Cond.Broadcast(). The magic at play here is just a little
too much for golangci-lint, as we take the address of queueMutex and this is
mostly used in archiver.go; the variable still gets flagged as unused.
* archiver: tests: fix several timing nits
Once we've signaled a cond var, it may take some small amount of time for
the goroutines released to hit the spot we're wanting them to be at. Give
them an appropriate amount of time.
* archiver: tests: no underscore in var name, ungh
* archiver: tests: Test* is run in a separate context than TestMain
We must setup the mutex/cond variables at the beginning of any test that's
going to use it, or else these will be nil when the test is actually ran.
* archiver: tests: hopefully final tweak
Things got shuffled around such that we carefully build up and release
requests from the queue, so we can validate the state of the queue at each
step. Fix some assertions that no longer hold true as fallout.
* repo: Download: restore some semblance of previous behavior
When archival was made async, the GET endpoint was only useful if a previous
POST had initiated the download. This commit restores the previous behavior,
to an extent; we'll now submit the archive request there and return a
"202 Accepted" to indicate that it's processing if we didn't manage to
complete the request within ~2 seconds of submission.
This lets a client directly GET the archive, and gives them some indication
that they may attempt to GET it again at a later time.
* archiver: tests: simplify a bit further
We don't need to risk failure and use time.ParseDuration to get 2 *
time.Second.
else if isn't really necessary if the conditions are simple enough and lead
to the same result.
* archiver: tests: resolve potential source of flakiness
Increase all timeouts to 10 seconds; these aren't hard-coded sleeps, so
there's no guarantee we'll actually take that long. If we need longer to
not have a false-positive, then so be it.
While here, various assert.{Not,}Equal arguments are flipped around so that
the wording in error output reflects reality, where the expected argument is
second and actual third.
* archiver: setup infrastructure for notifying consumers of completion
This API will *not* allow consumers to subscribe to specific requests being
completed, just *any* request being completed. The caller is responsible for
determining if their request is satisfied and waiting again if needed.
* repo: archive: make GET endpoint synchronous again
If the request isn't complete, this endpoint will now submit the request and
wait for completion using the new API. This may still be susceptible to
timeouts for larger repos, but other endpoints now exist that the web
interface will use to negotiate its way through larger archive processes.
* archiver: tests: amend test to include WaitForCompletion()
This is a trivial one, so go ahead and include it.
* archiver: tests: fix test by calling NewContext()
The mutex is otherwise uninitialized, so we need to ensure that we're
actually initializing it if we plan to test it.
* archiver: tests: integrate new WaitForCompletion a little better
We can use this to wait for archives to come in, rather than spinning and
hoping with a timeout.
* archiver: tests: combine numQueued declaration with next-instruction assignment
* routers: repo: reap unused archiving flag from DownloadStatus()
This had some planned usage before, indicating whether this request
initiated the archival process or not. After several rounds of refactoring,
this use was deemed not necessary for much of anything and got boiled down
to !complete in all cases.
* services: archiver: restructure to use a channel
We now offer two forms of waiting for a request:
- WaitForCompletion: wait for completion with no timeout
- TimedWaitForCompletion: wait for completion with timeout
In both cases, we wait for the given request's cchan to close; in the latter
case, we do so with the caller-provided timeout. This completely removes the
need for busy-wait loops in Download/InitiateDownload, as it's fairly clean
to wait on a channel with timeout.
* services: archiver: use defer to unlock now that we can
This previously carried the lock into the goroutine, but an intermediate
step just added the request to archiveInProgress outside of the new
goroutine and removed the need for the goroutine to start out with it.
* Revert "archiver: tests: combine numQueued declaration with next-instruction assignment"
This reverts commit bcc5214023.
Revert "archiver: tests: integrate new WaitForCompletion a little better"
This reverts commit 9fc8bedb56.
Revert "archiver: tests: fix test by calling NewContext()"
This reverts commit 709c35685e.
Revert "archiver: tests: amend test to include WaitForCompletion()"
This reverts commit 75261f56bc.
* archiver: tests: first attempt at WaitForCompletion() tests
* archiver: tests: slight improvement, less busy-loop
Just wait for the requests to complete in order, instead of busy-waiting
with a timeout. This is slightly less fragile.
While here, reverse the arguments of a nearby assert.Equal() so that
expected/actual are correct in any test output.
* archiver: address lint nits
* services: archiver: only close the channel once
* services: archiver: use a struct{} for the wait channel
This makes it obvious that the channel is only being used as a signal,
rather than anything useful being piped through it.
* archiver: tests: fix expectations
Move the close of the channel into doArchive() itself; notably, before these
goroutines move on to waiting on the Release cond.
The tests are adjusted to reflect that we can't WaitForCompletion() after
they've already completed, as WaitForCompletion() doesn't indicate that
they've been released from the queue yet.
* archiver: tests: set cchan to nil for comparison
* archiver: move ctx.Error's back into the route handlers
We shouldn't be setting this in a service, we should just be validating the
request that we were handed.
* services: archiver: use regex to match a hash
This makes sure we don't try and use refName as a hash when it's clearly not
one, e.g. heads/pull/foo.
* routers: repo: remove the weird /archive/status endpoint
We don't need to do this anymore, we can just continue POSTing to the
archive/* endpoint until we're told the download's complete. This avoids a
potential naming conflict, where a ref could start with "status/"
* archiver: tests: bump reasonable timeout to 15s
* archiver: tests: actually release timedReq
* archiver: tests: run through inFlight instead of manually checking
While we're here, add a test for manually re-processing an archive that's
already been complete. Re-open the channel and mark it incomplete, so that
doArchive can just mark it complete again.
* initArchiveLinks: prevent default behavior from clicking
* archiver: alias gitea's context, golang context import pending
* archiver: simplify logic, just reconstruct slices
While the previous logic was perhaps slightly more efficient, the
new variant's readability is much improved.
* archiver: don't block shutdown on waiting for archive
The technique established launches a goroutine to do the wait,
which will close a wait channel upon termination. For the timeout
case, we also send back a value indicating whether the timeout was
hit or not.
The timeouts are expected to be relatively small, but still a multi-
second delay to shutdown due to this could be unfortunate.
* archiver: simplify shutdown logic
We can just grab the shutdown channel from the graceful manager instead of
constructing a channel to halt the caller and/or pass a result back.
* Style issues
* Fix mis-merge
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Add team support for review request
Block #11355
Signed-off-by: a1012112796 <1012112796@qq.com>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Andrew Thornton <art27@cantab.net>
* Restrict TLS connections to 1.2 minimum
* Set Argon2 as the default KDF
* Fix user.yml
* Remove TLS minversion changes
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Add migration as per @techknowlogick
Signed-off-by: Andrew Thornton <art27@cantab.net>
* set the password algo in the fixtures
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Remove the v148 migration - it needs recreate table to change the defaults
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Nadim Kobeissi <nadim@symbolic.software>
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes#7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
* Add fixture gen tool and fix "access" test
* Close file before exiting
* Add missing repo_unit for repo id: 5
* Fix count on TestAPIOrgRepos
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
* Restricted users (#4334): initial implementation
* Add User.IsRestricted & UI to edit it
* Pass user object instead of user id to places where IsRestricted flag matters
* Restricted users: maintain access rows for all referenced repos (incl public)
* Take logged in user & IsRestricted flag into account in org/repo listings, searches and accesses
* Add basic repo access tests for restricted users
Signed-off-by: Manush Dodunekov <manush@stendahls.se>
* Mention restricted users in the faq
Signed-off-by: Manush Dodunekov <manush@stendahls.se>
* Revert unnecessary change `.isUserPartOfOrg` -> `.IsUserPartOfOrg`
Signed-off-by: Manush Dodunekov <manush@stendahls.se>
* Remove unnecessary `org.IsOrganization()` call
Signed-off-by: Manush Dodunekov <manush@stendahls.se>
* Revert to an `int64` keyed `accessMap`
* Add type `userAccess`
* Add convenience func updateUserAccess()
* Turn accessMap into a `map[int64]userAccess`
Signed-off-by: Manush Dodunekov <manush@stendahls.se>
* or even better: `map[int64]*userAccess`
* updateUserAccess(): use tighter syntax as suggested by lafriks
* even tighter
* Avoid extra loop
* Don't disclose limited orgs to unauthenticated users
* Don't assume block only applies to orgs
* Use an array of `VisibleType` for filtering
* fix yet another thinko
* Ok - no need for u
* Revert "Ok - no need for u"
This reverts commit 5c3e886aab.
Co-authored-by: Antoine GIRARD <sapk@users.noreply.github.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
* add "before" query to ListIssueComments and ListRepoIssueComments
* Add TEST
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Antoine GIRARD <sapk@users.noreply.github.com>
* test: add current attachement responses
* refactor: check if attachement is linked and accessible by user
* chore: clean TODO
* fix: typo attachement -> attachment
* revert un-needed go.sum change
* refactor: move models logic to models
* fix TestCreateIssueAttachment which was wrongly successful
* fix unit tests with unittype added
* fix unit tests with changes
* use a valid uuid format for pgsql int. test
* test: add unit test TestLinkedRepository
* refactor: allow uploader to access unlinked attachement
* add missing blank line
* refactor: move to a separate function repo.GetAttachment
* typo
* test: remove err test return
* refactor: use repo perm for access checking generally + 404 for all reject
* dont insert "-1" in any case to issue.poster_id
* Make sure API cant override importand fields
* code format
* fix lint
* WIP test
* add missing poster_id
* fix test
* user.IsGhost handle nil
* CI.restart()
* make sure no -1 is realy added
* CI.restart()
* @lunny suggestion remove some not allowed fields
* seperate issue.LoadMilestone
* load milestone and return it on IssueEdit via API
* extend Test for TestAPIEditIssue
* fix fixtures
* declare allowedColumnsUpdateIssueByAPI only once
* Update Year
* no var just write id drecty into func cal
Co-authored-by: Lauris BH <lauris@nix.lv>
* reject reactions wich ar not allowed
* dont duble check CreateReaction now throw ErrForbiddenIssueReaction
* add /repos/{owner}/{repo}/issues/comments/{id}/reactions endpoint
* add Find Functions
* fix some swagger stuff + add issue reaction endpoints + GET ReactionList now use FindReactions...
* explicite Issue Only Reaction for FindReactionsOptions with "-1" commentID
* load issue; load user ...
* return error again
* swagger def canged after LINT
* check if user has ben loaded
* add Tests
* better way of comparing results
* add suggestion
* use different issue for test
(dont interfear with integration test)
* test dont compare Location on timeCompare
* TEST: add forbidden dubble add
* add comments in code to explain
* add settings.UI.ReactionsMap
so if !setting.UI.ReactionsMap[opts.Type] works
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}